分布式环境的特点
分布性
并发性:程序运行过程中,并发操作是很常见的,比如同一个分布式系统中的多个节点,同时访问一个共享资源,比如数据库、分布式存储。
无序性:进程之间的消息通信,会出现顺序不一致问题。
分布式环境下面临的问题
网络通信:网络本身的不可靠性。
网络分区(脑裂):当网络发生异常,分布式系统中部分节点之间的网络延迟不断增大,最终导致组成分布式架构的所有节点,只有部分节点能够正常通信。
三态:在分布式架构里面,除了成功、失败、超时。
分布式事务
Zookeeper 是什么
Zookeeper 是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。
Zookeeper 是一个基于观察者模式的分布式服务管理框架,它负责存储和管理应用的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,
Zookeeper 就将负责通知已经在Zookeeper 上注册的那些观察者做出相应的反应,从而实现集群中类似Master/Slave管理模式。
Zookeeper = 文件系统 + 通知机制。
Znode 有两种类型
临时(ephemeral):客户端和服务端断开连接后,创建的节点自己删除;
持久(persistent):客户端和服务端断开连接后,创建的节点不删除;Znode 有四种形式的目录节点(默认是persistent)
(1)持久目录节点(persistent)
客户端和服务端断开连接后,该节点依旧存在。
(2)持久顺序编号目录节点(persistent_sequential)
客户端和服务端断开连接后,该节点依旧存在,只是zookeeper 给该节点名称进行顺序编号。
(3)临时目录节点(ephemeral)
客户端和服务端断开连接后,该节点被删除。
(4)临时顺序编号目录节点(ephemeral_sequential)
客户端和服务端断开连接后,该节点被删除,只是zookeeper 给该节点名称进行顺序编号。
特点
- zookeeper 有一个领导者(Leader),多个跟随者(Follower)组成的集群;
- Leader 负责进行投票的发起和决议,更新系统状态;
- Follower 用于接收客户请求并向客户端返回结果,在选举Leader过程中参与投票;
- 集群中只要有半数以上节点存活,zookeeper 集群就能正常服务;
- 全局数据一致性,每个server保存一份相同的数据副本,client 无论连接到哪个server,数据都是一致的;
- 更新请求顺序执行,来自同一个client的更新请求按其发送顺序依次执行;
- 数据更新原子性,一次数据更新要么成功,要么失败;
- 实时性,在一定时间范围内,client能读到最新数据。
选举机制
- 半数机制:集群中半数以上机器存活,集群可用。所以zookeeper 适合在奇数台机器上部署。
- zookeeper 虽然在配置文件中没有指定master和salve。
但是zookeeper工作时,是有一个节点为Leader,其他节点为follower。Leader 是通过内部选举机制临时产生的。
经典的CAP/BASE理论
CAP
https://www.ruanyifeng.com/blog/2018/07/cap.html
指出分布式存储不可能同时满足三个条件
一致性(Consistency):每次读取要么获得最近写入的数据,要么获得一个错误;
可用性(Availability):每次请求都能获得一个(非错误)响应,但不保证返回的是最新写入的数据;
分区容错性(Partition tolerance):尽管任意数量的消息被节点间的网络丢失(或延迟),系统仍继续运行。
BASE
基本可用
软状态
最终一致性
应用场景
- 分布式消息同步和协调机制
- 服务器节点动态上下线
- 统一配置管理
- 负载均衡
- 集群管理
下载安装本地模式
下载地址:http://mirror.bit.edu.cn/apache/zookeeper/
选择stable版本下载zookeeper-3.4.10.tar.gz
解压后目录如下:
bin目录存放启动zookeeper的脚本。以.sh结尾的脚本运行于UNIX平台(Linux、Mac OS X等),以.cmd结尾的脚本则运行于Windows。
conf目录保存配置文件。
lib目录包括Java的jar文件,它们是允许zookeeper所需要的第三方文件。
进入conf目录下,重命名mv zoo_sample.cfg zoo.cfg
编辑zoo.cfg配置文件
主要修改一下配置:
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/log
1 | # The number of milliseconds of each tick |
启动服务1
# ./bin/zkServer.sh start
这个命令使zookeeper在后台运行,如果在前台运行以便查看服务输出,可以通过以下命令运行1
# ./bin/zkServer.sh start-foreground
顺利的话,现在zookeeper已经启动了,可以通过jps 查看zookeeper进程。
停止zookeeper服务1
# ./bin/zkServer.sh stop
使用客户端连接到服务端1
# bin/zkCli.sh
输出信息如下: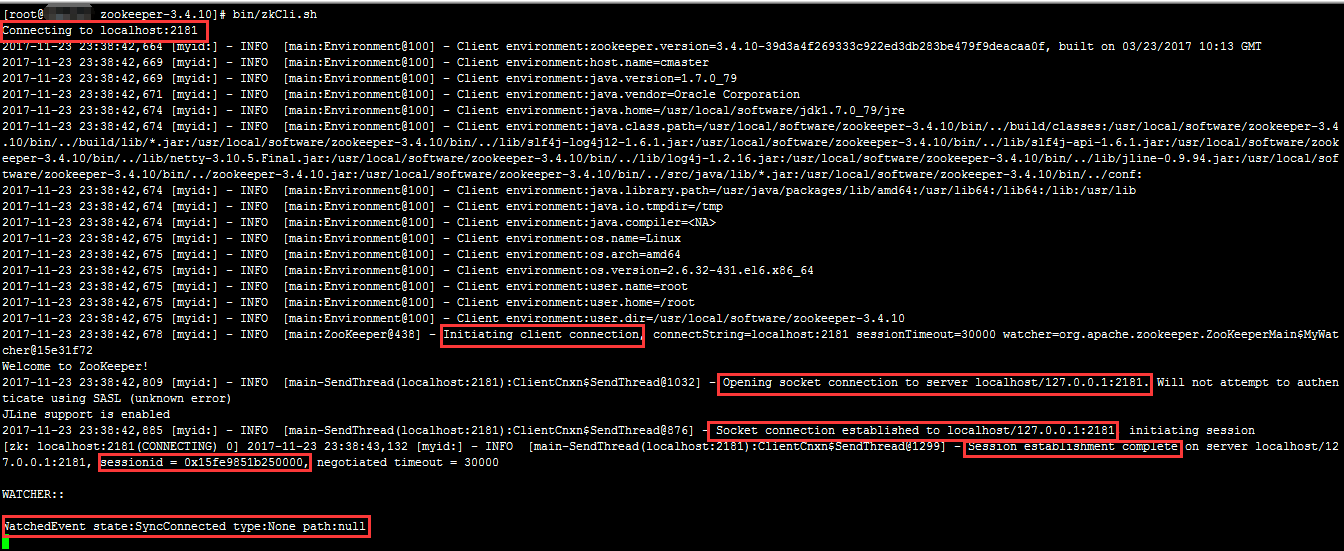
执行ls / 查看根下所有的znode
创建/workers 节点,并在这个节点上保存数据”mydata”
删除节点:delete /workers
退出客户端连接:quit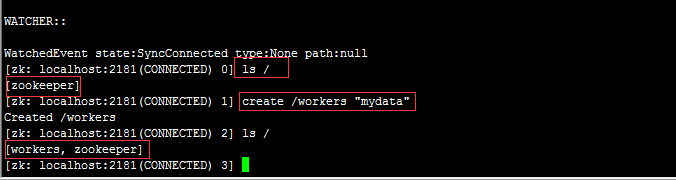
七张图彻底讲清楚ZooKeeper分布式锁的实现原理【石杉的架构笔记】
分布式锁的几种实现方式
基于 Redis 的分布式锁
