阅读原文
Reading compiled Java bytecode can be tedious, even for experienced Java developers.
即使对于经验丰富的Java开发人员来说,阅读编译后的Java字节码也可能很乏味。
Why do we need to know about such low-level stuff in the first place?
首先,我们为什么需要知道这些底层的东西呢?
Here is a simple scenario that happened to me last week:
下面是上周发生在我身上的一个简单场景:
I had made some code changes on my machine a long time ago, compiled a JAR,
很久以前,我在自己的机器上修改了一些代码,编译成一个JAR包,
and deployed it on a server to test a potential fix for a performance issue.
并且部署在一台服务器上以测试性能问题的潜在修复。
Unfortunately, the code was never checked into a version control system,
不幸的是,这些代码从没有被检入版本控制系统,
and for whatever reason, the local changes were deleted without a trace.
并且由于一些原因,本地的修改被删除的毫无踪迹。
After a couple of months, I needed those changes in source form again (which took quite an effort to come up with),
几个月后,我再一次需要这些修改的源码(这需要付出很大的努力),
but I could not find them!
但是我没有找到它们!
Luckily the compiled code still existed on that remote server.
幸运的是编译后的代码依然存在远程服务器上。
So with a sigh of relief, I fetched the JAR again and opened it using a decompiler editor…
于是松了一口气,我再一次获取到JAR包并且使用反编译编辑器打开它…
Only one problem: The decompiler GUI is not a flawless tool, and out of the many classes in that JAR,
唯一的问题:反编译器GUI不是一个完美的工具,而且在这个JAR中有很多类,
for some reason, only the specific class I was looking to decompile caused a bug in the UI whenever I opened it, and the decompiler to crash!
由于某种原因,无论什么时候,我用反编译工具打开要查看的特定类就会引起一个UI bug,反编译器会崩溃!
Desperate times call for desperate measures. Fortunately, I was familiar with raw bytecode,
绝望的时候需要孤注一掷的对策。幸运的是,我熟悉原生字节码,
and I’d rather take some time manually decompiling some pieces of the code rather than work through the changes and testing them again.
并且,我宁愿花费一些时间手工反编译代码也不愿对更改进行重新测试。
Since I still remembered at least where to look in the code,
因为我至少还记得在哪里查看代码,
reading bytecode helped me pinpoint the exact changes and construct them back in source form.
(I made sure to learn from my mistake and preserve them this time!)
阅读字节码帮助我精确的定位实际改变的地方,并且使用源码的形式构造它们(我一定要从我的错误中吸取教训,这次一定要记住!)。
The nice thing about bytecode is that you learn its syntax once, then it applies on all Java supported platforms —
字节码的好处是你一旦学习它的语法,它可以应用于所有Java支持的平台 -
because it is an intermediate representation of the code, and not the actual executable code for the underlying CPU.
因为它表示一个中间代码,不是实际在CPU上执行的代码。
Moreover, bytecode is simpler than native machine code because the JVM architecture is rather simple,
另外,字节码比本地机器码简单因为Java虚拟机架构相当简单。
hence simplifying the instruction set. Yet another nice thing is that all instructions in this set are fully documented by Oracle.
因此简化了指令集,然而,另一件好事是指令集中所有指令完全由Oracle提供。
Before learning about the bytecode instruction set though, let’s get familiar with a few things about the JVM that are needed as a prerequisite.
学习字节码指令集之前, 让我们先熟悉一下JVM的基础,作为学习指令集的前提条件。
JVM Data Types
JVM数据类型
Java is statically typed, which affects the design of the bytecode instructions such that an instruction expects itself to operate on values of specific types.
Java是静态类型的,这影响了指令字节码的设计,使得一个指令期望自己去操作指定类型的值。
For example, there are several add instructions to add two numbers: iadd, ladd, fadd, dadd.
例如,有几个两个数的相加指令:iadd, ladd, fadd, dadd。
They expect operands of type, respectively, int, long, float, and double.
它们期望操作的类型分别是int, long, float, 和 double。
The majority of bytecode has this characteristic of having different forms of the same functionality depending on the operand types.
根据操作类型不同,相同的功能有不同的形式,大多数字节码具有的特征。
The data types defined by the JVM are:
JVM定义的数据类型:
Primitive types:
原生类型:Numeric types: byte (8-bit 2’s complement), short (16-bit 2’s complement), int (32-bit 2’s complement), long (64-bit 2’s complement), char (16-bit unsigned Unicode), float (32-bit IEEE 754 single precision FP), double (64-bit IEEE 754 double precision FP)
数字类型:byte(8bit), short(16bit), int(32bit), long(64bit), char(16bit), float(32bit), double(64bit)boolean type
布尔类型returnAddress: pointer to instruction
返回地址:指向指令
Reference types:
引用类型Class types
类类型Array types
数组类型Interface types
接口类型
The boolean type has limited support in bytecode.
字节码对布尔类型的支持有限制。
For example, there are no instructions that directly operate on boolean values.
例如,没有指令直接操作布尔类型。
Boolean values are instead converted to int by the compiler and the corresponding int instruction is used.
编译器将boolean值转换为int,并使用相应的int指令。
Java developers should be familiar with all of the above types, except returnAddress, which has no equivalent programming language type.
Java开发人员应该熟悉上述所有类型,除了returnAddress类型,它没有等价的编程语言类型。
Stack-Based Architecture
基于栈的架构
The simplicity of the bytecode instruction set is largely due to Sun having designed a stack-based VM architecture, as opposed to a register-based one.
字节码指令集的简单性很大程度上归功于Sun设计了基于栈的VM 架构,而不是基于寄存器的架构。
There are various memory components used by a JVM process, but only the JVM stacks need to be examined in detail to essentially be able to follow bytecode instructions:
JVM 进程使用了各种内存组件,但是只需要详细检查JVM 栈,以便能够遵循字节码指令:
PC register: for each thread running in a Java program, a PC register stores the address of the current instruction.
程序计数器:对于每个运行在Java进程中的线程,PC 寄存器存储当前指令的地址。
JVM stack: for each thread, a stack is allocated where local variables, method arguments,
and return values are stored. Here is an illustration showing stacks for 3 threads.
JVM 栈:对于每个线程,被申请的栈用于存储本地变量,方法参数,返回值。下面是显示3个线程的堆栈图。

Heap: memory shared by all threads and storing objects (class instances and arrays).
堆:堆内存被所有线程共享,用来存储对象(类实例和数组)。
Object deallocation is managed by a garbage collector.
对象的释放由垃圾收集器管理。

Method area: for each loaded class, it stores the code of methods and a table of symbols
(e.g. references to fields or methods) and constants known as the constant pool.
方法区:对于每个加载的类,它存储了方法代码和符号表(例如,对字段或方法的引用)。和称为常量池的常量。
A JVM stack is composed of frames, each pushed onto the stack when a method is invoked and
popped from the stack when the method completes (either by returning normally or by throwing an exception).
JVM 栈由栈帧组成,每个栈帧在方法调用时被压入栈,方法完成时从栈顶弹出(通过正常返回或抛出异常)。
Each frame further consists of:
每个栈帧还包括:
An array of local variables, indexed from 0 to its length minus 1.
The length is computed by the compiler.
A local variable can hold a value of any type, except long and double values, which occupy two local variables.
局部变量的数组,索引从0 到长度减1,长度是由编译器计算。
局部变量可以保存任意类型的值,long 和 double 类型的值除外,它们占用两个局部变量。An operand stack used to store intermediate values that would act as operands for instructions,
or to push arguments to method invocations.
一个操作数栈用于存储中间值,该中间值将充当指令的操作数,或者压入参数到方法调用。
Bytecode Explored
探索字节码
With an idea about the internals of a JVM, we can look at some basic bytecode example generated from sample code.
Each method in a Java class file has a code segment that consists of a sequence of instructions,
each having the following format:
了解 JVM 的内部结构,我们可以看一下从示例代码生成的一些基本字节码示例。
Java class文件中的每个方法都有一个由一系列指令组成的代码片段,每个都有以下格式:1
opcode (1 byte) operand1 (optional) operand2 (optional) ...
That is an instruction that consists of one-byte opcode and zero or more operands that contain the data to operate.
这是由一个字节的操作码和零个或多个操作数组成的一个指令,
Within the stack frame of the currently executing method, an instruction can push or pop values onto the operand stack,
and it can potentially load or store values in the array local variables. Let’s look at a simple example:
在当前正在执行的方法的栈帧内部,一个指令可以压入或弹出值到一个操作数栈,并且它可以在数组局部变量中加载或存储值。
让我们看一个简单示例:
1 | public static void main(String[] args) { |
In order to print the resulting bytecode in the compiled class (assuming it is in a file Test.class),
we can run the javap tool:
为了在编译的类中打印生成的字节码(假设它在一个Test.class文件中),我们可以运行javap 工具:1
javap -v Test.class
And we get:
然后我们得到:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=4, args_size=1
0: iconst_1
1: istore_1
2: iconst_2
3: istore_2
4: iload_1
5: iload_2
6: iadd
7: istore_3
8: return
...
We can see the method signature for the main method,
a descriptor that indicates that the method takes an array of Strings ([Ljava/lang/String; ),
and has a void return type (V ).
A set of flags follow that describe the method as public (ACC_PUBLIC) and static (ACC_STATIC).
我们可以看到主方法的方法签名,一个描述符表示该方法使用字符串数组([Ljava/lang/String; ),并且具有空返回值类型(V)。
下面的一组flags描述了方法是公开的(ACC_PUBLIC) 并且是静态的 (ACC_STATIC)。
The most important part is the Code attribute,
最重要的部分是代码属性,
which contains the instructions for the method along with information
such as the maximum depth of the operand stack (2 in this case),
and the number of local variables allocated in the frame for this method (4 in this case).
其中包含方法说明和信息,例如操作数栈的最大深度(在本例中为2),以及此方法在栈帧中分配的局部变量数(在本例中为4)。
All local variables are referenced in the above instructions except the first one (at index 0),
which holds the reference to the args argument.
The other 3 local variables correspond to variables a, b and c in the source code.
除了第一个(索引0)之外,上述指令中引用了所有的局部变量,它保存了对args参数的引用。
其他3个局部变量对应源码中的变量 a, b 和c。
The instructions from address 0 to 8 will do the following:
从地址0到8的指令将执行以下操作:
iconst_1: Push the integer constant 1 onto the operand stack.
iconst_1:将整型常量1压入到操作数栈。
istore_1: Pop the top operand (an int value) and store it in local variable at index 1, which corresponds to variable a.
istore_1:弹出顶部操作数(一个整型值)并将其存储在索引1的局部变量中,该变量对应于变量a。
iconst_2: Push the integer constant 2 onto the operand stack.
iconst_2: 将整型常量2压入到操作数栈。
istore_2: Pop the top operand int value and store it in local variable at index 2, which corresponds to variable b.
istore_2:弹出顶部操作数整型值,并将其存储在索引2的局部变量中,该变量对应于变量b。
iload_1: Load the int value from local variable at index 1 and push it onto the operand stack.
iload_1: 从索引1的局部变量加载整型值,并且将它压入操作数栈。
iload_2: Load the int value from the local variable at index 2 and push it onto the operand stack.
iload_2: 从索引2的局部变量加载整型值,并且将它压入操作数栈。
iadd: Pop the top two int values from the operand stack, add them, and push the result back onto the operand stack.
iadd: 从操作数栈顶部弹出两个整型值,将它们相加,并且将结果压回到操作数栈。
istore_3: Pop the top operand int value and store it in local variable at index 3, which corresponds to variable c.
istore_3: 弹出操作数顶部的整型值,并将其存储在索引3的局部变量中,该变量对应于变量c。
return: Return from the void method.
return: 从void 方法返回。
Each of the above instructions consists of only an opcode, which dictates exactly the operation to be executed by the JVM.
上面的每个指令仅由一个操作码组成,它精确地指示JVM要执行的操作。
Method Invocations
方法调用
In the above example, there is only one method, the main method.
Let’s assume that we need to a more elaborate computation for the value of variable c,
and we decide to place that in a new method called calc:
在上面示例中只有一个方法,主方法。
让我们假设我们需要对变量c的值进行一个更复杂的计算,我们决定将其放在一个名为calc的新方法中:1
2
3
4
5
6
7
8public static void main(String[] args) {
int a = 1;
int b = 2;
int c = calc(a, b);
}
static int calc(int a, int b) {
return (int) Math.sqrt(Math.pow(a, 2) + Math.pow(b, 2));
}
Let’s see the resulting bytecode:
让我们看看生成的字节码:
1 | public static void main(java.lang.String[]); |
The only difference in the main method code is that instead of having the iadd instruction,
we now an invokestatic instruction, which simply invokes the static method calc.
The key thing to note is that the operand stack contained the two arguments that are passed to the method calc.
In other words, the calling method prepares all arguments of the to-be-called method by pushing them
onto the operand stack in the correct order.
invokestatic (or a similar invoke instruction, as will be seen later) will subsequently pop these arguments,
and a new frame is created for the invoked method where the arguments are placed in its local variable array.
在主方法代码中唯一不同的是,不是使用iadd 命令,我们现在是一个 invokestatic 命令,它只是调用静态方法calc。
关键需要注意的是,操作数栈包含传递给方法calc的两个参数。
换句话说,调用方法准备被调用方法的所有参数,通过以正确的顺序压入它们到操作数栈。
invokestatic(或者类似的调用命令,稍后将会看到)将随后弹出这些参数,
并为调用的方法创建一个新的栈帧,其中参数放在其局部变量数组中。
We also notice that the invokestatic instruction occupies 3 bytes by looking at the address, which jumped from 6 to 9.
This is because, unlike all instructions seen so far,
invokestatic includes two additional bytes to construct the reference to the method to be invoked (in addition to the opcode).
The reference is shown by javap as #2, which is a symbolic reference to the calc method,
which is resolved from the constant pool described earlier.
我们也注意到通过查看地址 invokestatic 命令占用3个字节,地址从6跳到9。
这是因为不像目前看到的所有指令,invokestatic 指令包含两个附加的字节来构造调用方法的引用(除了操作码)。
该引用由javap 显示为2,它是calc方法的符号引用,这是从前面描述的常量池中解析出来的。
The other new information is obviously the code for the calc method itself.
It first loads the first integer argument onto the operand stack (iload_0).
The next instruction, i2d, converts it to a double by applying widening conversion.
The resulting double replaces the top of the operand stack.
其他新信息显然是calc方法本身的代码。
它首先加载第一个整型参数到操作数栈(iload_0)。
下一个指令i2d,通过应用扩展转换将其转换为double。
结果double 替换操作数栈顶。
The next instruction pushes a double constant 2.0d (taken from the constant pool) onto the operand stack.
Then the static Math.pow method is invoked with the two operand values prepared so far
(the first argument to calc and the constant 2.0d).
When the Math.pow method returns, its result will be stored on the operand stack of its invoker.
This can be illustrated below.
下一个指令压入一个double类型的常量2.0d(取自常量池)到操作数栈。
然后使用到目前为止准备的两个操作数值调用静态方法Math.pow(calc方法的第一个参数和常量2.0d)。
当Math.pow 方法返回时,其结果存储在其调用者的操作数栈。这可以在下面说明。
The same procedure is applied to compute Math.pow(b, 2):
计算Math.pow(b, 2)是相似的过程:
The next instruction, dadd, pops the top two intermediate results, adds them, and pushes the sum back to the top.
Finally, invokestatic invokes Math.sqrt on the resulting sum,
and the result is cast from double to int using narrowing conversion (d2i).
The resulting int is returned to the main method, which stores it back to c (istore_3).
下一个指令dadd 弹出栈顶的两个中间结果,相加,将相加结果压回栈顶。
最后,invokestatic 调用Math.sqrt
并且使用强制转换(d2i)将结果从double 转换成int。
int类型的结果被返回到main方法,存储到变量c(istore_3)。
Instance Creations
创建实例
Let’s modify the example and introduce a class Point to encapsulate XY coordinates.
让我们修改示例并引入Point类来封装XY坐标。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class Test {
public static void main(String[] args) {
Point a = new Point(1, 1);
Point b = new Point(5, 3);
int c = a.area(b);
}
}
class Point {
int x, y;
Point(int x, int y) {
this.x = x;
this.y = y;
}
public int area(Point b) {
int length = Math.abs(b.y - this.y);
int width = Math.abs(b.x - this.x);
return length * width;
}
}
The compiled bytecode for the main method is shown below:
main方法的编译字节码如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=4, locals=4, args_size=1
0: new #2 // class test/Point
3: dup
4: iconst_1
5: iconst_1
6: invokespecial #3 // Method test/Point."<init>":(II)V
9: astore_1
10: new #2 // class test/Point
13: dup
14: iconst_5
15: iconst_3
16: invokespecial #3 // Method test/Point."<init>":(II)V
19: astore_2
20: aload_1
21: aload_2
22: invokevirtual #4 // Method test/Point.area:(Ltest/Point;)I
25: istore_3
26: return
The new instructions encountereted here are new , dup, and invokespecial.
这里遇到的新指令是new, dup 和 invokespecial。
Similar to the new operator in the programming language,
the new instruction creates an object of the type specified in the operand passed to it
(which is a symbolic reference to the class Point).
Memory for the object is allocated on the heap, and a reference to the object is pushed on the operand stack.
与编程语言中的new 运算符类似,new 指令创建一个传递给它的操作数中指定类型的对象(这是Point类的符号引用)。
对象的内存在堆上分配,对象的引用是被压入操作数栈。
The dup instruction duplicates the top operand stack value,
which means that now we have two references the Point object on the top of the stack.
dup 指令复制操作数栈顶值,这意味着现在我们在栈顶有两个引用Point对象。
The next three instructions push the arguments of the constructor
(used to initialize the object) onto the operand stack,
and then invoke a special initialization method, which corresponds with the constructor.
接下来三个指令将构造方法(用于初始化对象)的参数压入到操作数栈上,然后调用一个特殊的初始化方法,该方法与构造方法对应。
The next method is where the fields x and y will get initialized.
After the method is finished, the top three operand stack values are consumed,
and what remains is the original reference to the created object (which is, by now, successfully initialized).
下一个方法是属性x 和 y 将得到初始化,方法完成后,顶部三个操作数值被消费,
剩下来的是对创建对象的原始引用(这时初始化成功)。
Next, astore_1 pops that Point reference and assigns it to the local variable at index 1
(the a in astore_1 indicates this is a reference value).
接下来,astore_1 弹出Point引用并将其分配给索引为1的局部变量(astore_1中的a表示这是引用值)。
The same procedure is repeated for creating and initializing the second Point instance,
which is assigned to variable b.
重复相似的过程来创建和初始化第二个Point实例,分配给变量b。

The last step loads the references to the two Point objects from local variables at indexes 1 and 2
(using aload_1 and aload_2 respectively), and invokes the area method using invokevirtual,
which handles dispatching the call to the appropriate method based on the actual type of the object.
最后一步从局部变量的索引1和2中加载对两个Point对象的引用(分别使用aload_1 和 aload_2指令),
并且使用invokevirtual 指令调用area方法,它处理根据对象的实际类型将调用到适当的方法。
For example, if the variable a contained an instance of type SpecialPoint that extends Point,
and the subtype overrides the area method, then the overriden method is invoked.
In this case, there is no subclass, and hence only one area method is available.
例如,如果变量a 包含一个继承了Point的SpecialPoint类型的实例,并且子类型重写了area方法,然后重写的方法被调用。
在这个例子中,没有子类,因此只有一个area方法是可用的。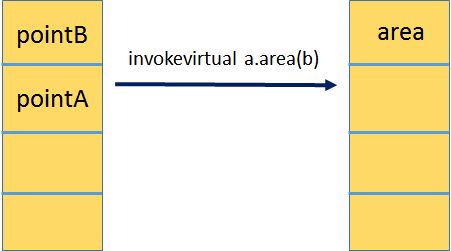
Note that even though the area method accepts one argument,
there are two Point references on the top of the stack.
注意,即使area方法接收一个参数,在栈顶有两个Point引用。
The first one (pointA, which comes from variable a) is actually the instance
on which the method is invoked (otherwise referred to as this in the programming language),
and it will be passed in the first local variable of the new frame for the area method.
The other operand value (pointB) is the argument to the area method.
第一个(PointA 来自变量a)是调用方法的实际实例(在编程语言中称为this),
它将在area方法的新帧的第一个局部变量中传递。另一个操作数值(pointB)是area方法的参数。
The Other Way Around
其他方式
You don’t need to master the understanding of each instruction
and the exact flow of execution to gain an idea about what the program does based on the bytecode at hand.
For example, in my case, I wanted to check if the code employed a Java stream to read a file,
and whether the stream was properly closed.
Now given the following bytecode, it is relatively easy to determine that indeed a stream is used
and most likely it is being closed as part of a try-with-resources statement.
你不需要掌握每个指令的意义,以及确切的执行流程,以便于根据字节码了解程序的功能。
例如,在我的情况下,我想检查代码是否使用Java流读取文件, 以及流是否正确关闭。
现在给出如下的字节码,它是相对容易的确定确实使用了流,并且很可能它是作为try-with-resources的一部分而被关闭的。
1 | public static void main(java.lang.String[]) throws java.lang.Exception; |
We see occurrences of java/util/stream/Stream where forEach is called,
preceded by a call to InvokeDynamic with a reference to a Consumer.
我们看到java/util/stream/Stream的出现在forEach被调用的地方,之前调用InvokeDynamic 并引用Consumer。
And then we see a chunk of bytecode that calls Stream.close along with branches that call Throwable.addSuppressed.
然后我们看到大块字节码调用Stream.close 以及调用Throwable.addSuppressed 的分支。
This is the basic code that gets generated by the compiler for a try-with-resources statement.
这是编译器为try-with-resources语句生成的基本代码。
Here’s the original source for completeness:
以下是完整的源码:
1 | public static void main(String[] args) throws Exception { |
Conclusion
结论
Thanks to the simplicity of the bytecode instruction set
and the near absence of compiler optimizations when generating its instructions,
disassembling class files could be one way to examine changes into
your application code without having the source, if that ever becomes a need.
由于字节码指令集的简化,并且在生成其指令时几乎没有编译器优化,
在你的应用程序代码没有源码,如果需要的话,反编译类文件可能是检查更改的一种方法。
